Adam은 현재 딥러닝에서 가장 효율이 좋은 옵티마이져 중에 하나이다, Adam에 대해서 이해하기 위해서는 우선 Momentum과 RMSProp의 개념을 알아야 한다.
내용은 유튜브 혁펜하임님의 Easy! 딥러닝을 참고했다(ㅎㅎ... 역시 명강의야..)

수식은 Adam을 설명하면서 하겠다.
우선 모멘텀은 다음과 같다


모멘텀은 이전의 그레디언트를 기억하라는 것이 중점이다. 당연히 가장 최신 그레디언트의 영향이 가장 크다.
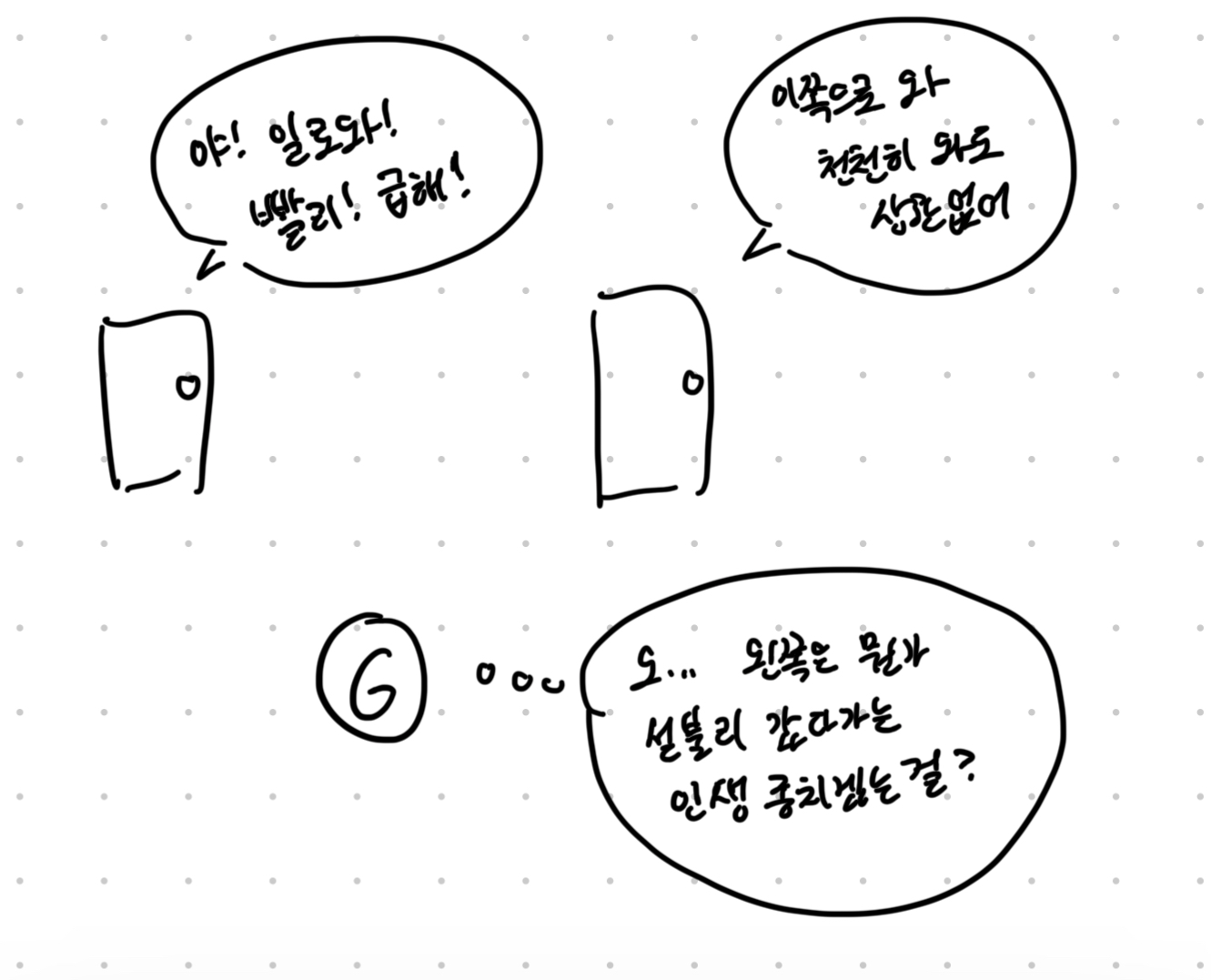
이게 무슨 소리냐면 아래 그림과 같다.

맨 처음에 이동했던 방향과 "반대 방향"으로 갈 경우, "엥 아까는 저기로 가라고 했었는데? 혹시 모르니까, 저쪽 방향도 고려해야겠다"인 것이라고 볼 수 있다.
RMSProp은 다음과 같다.
그레디언트는 초기 랜덤한 시작점에 의해 각 변수마다 기울기 값이 다르게 잡힐 것이다. 그러다 보니, 어느 방향으로는 크게 가야 하고, 어느 방향으로는 작게 가야 하는데, 여기서 중요한 것은 "섣불리 가지 않는 것"이다.
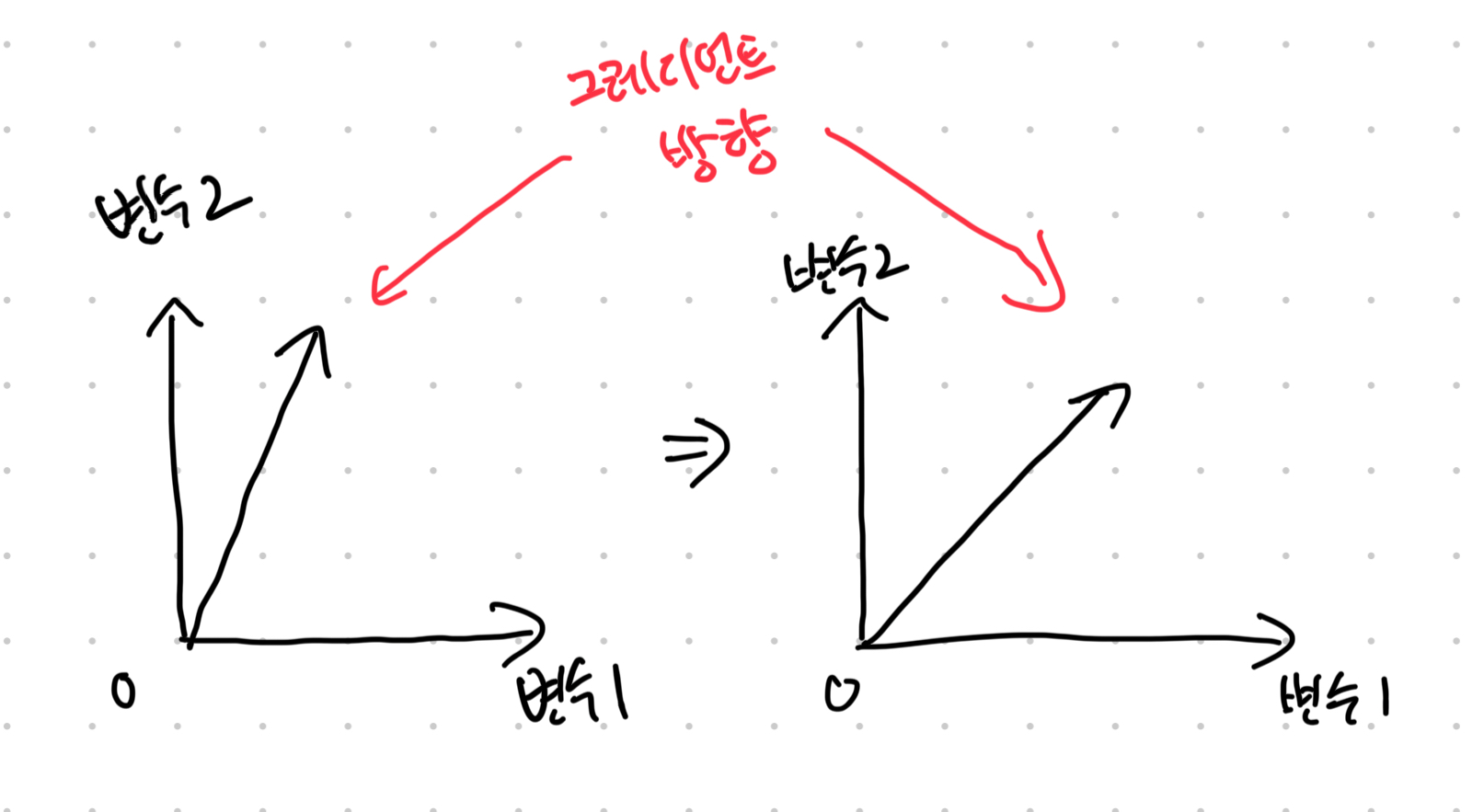
그래프로 살피면, 원래대로 라면, 다급하게 그레디언트를 부르는 문으로 가야 할 녀석이, 양쪽의 의견을 동일하게 듣는 것을 의미한다. 다르게 말하면, 가중치 값이 큰 곳으로는 적게 가고, 값이 작은 곳으로는 크게 가라는 것을 의미한다.
균등하게 가라는 말도 되지만, 완만하게 가라는 말도 된다. (혹은 안전빵으로 가라)
여기서 "그레디언트는 항상 contour과 수직하다"라는 개념이 있는데, 이부분은 아직 잘 모르겠다(아직 직관적이게 보이지 않는다, 공부를 더 해야겠다)->이제 이해했다, 다음 글은 너로 가겠다
아무튼 이렇게 Momentum과 RMSProp을 살펴봤는데, 이제 Adam을 적을 차례다.
Adam이란?
아담은 위에 두개를 합친 녀석이다.

이게 아담 논문의 수식인데, 여기는 각 변수들의 수식을 의미하고, 전체적인 계산식은 맨 아랫줄에 있다.

이렇게 생겼다, 알파는 lr(learning rate)이고, 기존의 가중치 세타를 업데이트 하는 식이니, 여기서 m과 v만 보면 된다.
우선 베타_1, 베타_2는 0과 1 사이의 임의값을 정해주는 하이퍼파라미터(사람이 정해주는 수치 값)이므로, 보기의 편리성을 위해 둘다 0.5로 잡아 준다(feat. 혁펜하임)
그럼 m과 v는 다음과 같다.
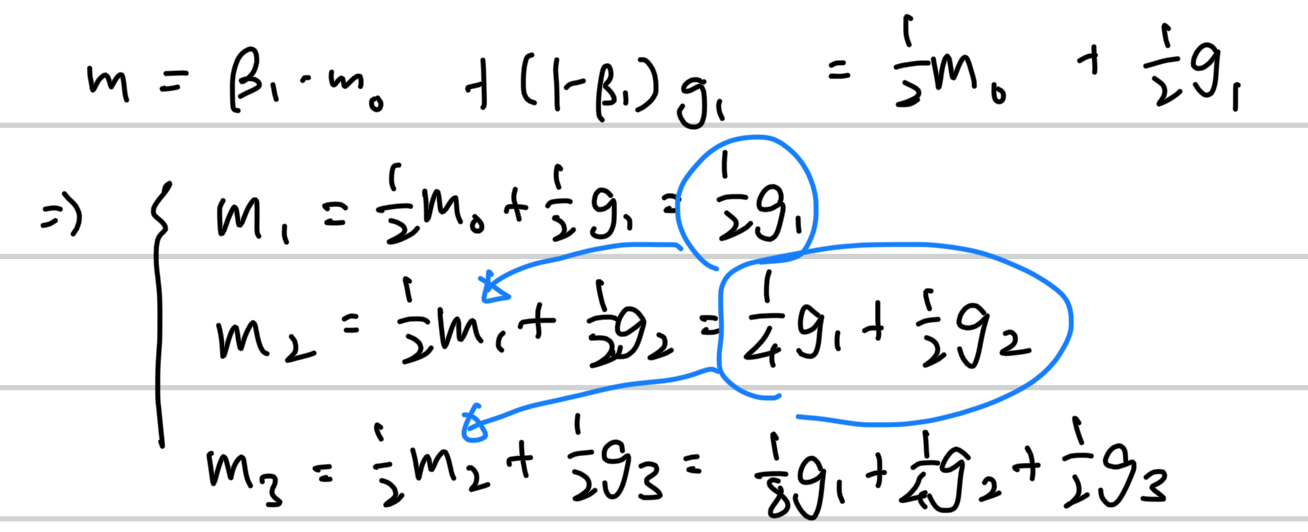
v도 똑같다(베타_1과 베타_2를 같은 값을 줬기 때문에 그렇다), 그저 gradient에 제곱이 들어갔을 뿐이다.

참고로 벡터는 본래 제곱이 불가능한 성질을 가지고 있기 때문에, 본 논문에서는 각 성분을 제곱한다는 의미로 표현한다는 것을 표시했다.
그리고 전체적인 수식을 보면, v는 루트를 씌우는 것을 볼 수 있다. 이것은 다시 말해 v는 gradient 벡터가 제곱을 하고, 루트를 씌워지는 L2-norm을 진행한다고 볼 수 있다 -> 벡터의 크기를 표시한다는 의미다.
다시말해, Momentum은 그레디언트의 방향을 좌지우지 하고, RMSProp은 크기를 좌지우지 한다는 것으로 나는 해석했다.
그럼 RMSProp의 기울기가 큰 방향은 적게가고 기울기가 작은 방향은 크게 가라는 것은 어디에 있는가? -> 이것이 v가 "분모"에 있는 이유다. (분모의 성질이 값이 크면 작아지고, 값이 작으면 커지는 것을 의미하기 때문이다)
그리고 v 옆에 숫자 3을 반전시킨 저녀석은, 그저 분모가 0이 되는 것을 방지하기 위한, 작은 상수를 의미한다.
'딥러닝' 카테고리의 다른 글
| 딥러닝에서 공간을 직관화 하기 위해 어떤 노력들이 있는가? (0) | 2024.11.13 |
|---|---|
| AutoEncoder를 공부하는 이유 (0) | 2024.11.12 |
| 데이터 정보를 "압축한다"와 "손실한다"는 뭐가 다른걸까? (0) | 2024.11.10 |
| 왜 자꾸 f1-score을 강조하는 것일까? (0) | 2024.11.09 |
| 딥러닝에서 수학은 도대체 무엇일까? (2) | 2024.11.08 |