
이번 문제는 s안에 있는 "모든 문자"가 t안에 "같은 순서"로 나열되어 있는지 확인하는 과정이다.
처음에는 인덱스를 활용해 접근을 하려고 했다.
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
if len(s) > len(t): return False
if s == '': return True
ind = []
for i in range(len(s)):
if s[i] not in t:
return False
else:
ind.append(t.index(s[i]))
new_ind = sorted(set(ind))
return ind == new_ind
접근 방식은 아래와 같다. 인덱스 위치를 "리스트"로 정리한 다음, 순서대로 정렬을 해도 원래와 동일한지 확인을 하는 것이었다.

여기서 set()는 집합의 의미이므로, "중복된 것을 제거할 때 사용된다" e.g. s = "baaaaa", t = "baaaaaaaaaa"
(그리고 sorted()는 리스트를 내뱉으므로 굳이 타입 변환을 해줄 필요가 없었다.)
하지만 제출할 때 다음과 같은 문제가 생겼다.
s = 'ab', t = 'baab'
output: False
expected: True
index()는 항상 앞에 있는 것을 차례대로 세기 때문에, "인덱스"를 활용한 접근 방식이 잘못된 것이다.
여기서 다른 방식으로 접근을 해야 했다.
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
if len(s) > len(t): return False
if s == '': return True
S, T = len(s), len(t)
cnt = 0
for i in range(T):
if t[i] == s[cnt]:
if cnt == S-1:
return True
cnt += 1
return False
기존의 방식에서는 하나의 리스트를 기준으로 참인지 불인지 확인 했는데, 여기서는 "숫자(cnt)" 하나로 참인지 불인지 구분하는 것이다.
참고로 cnt는 count의 약자로 카운트(횟수)를 의미한다.
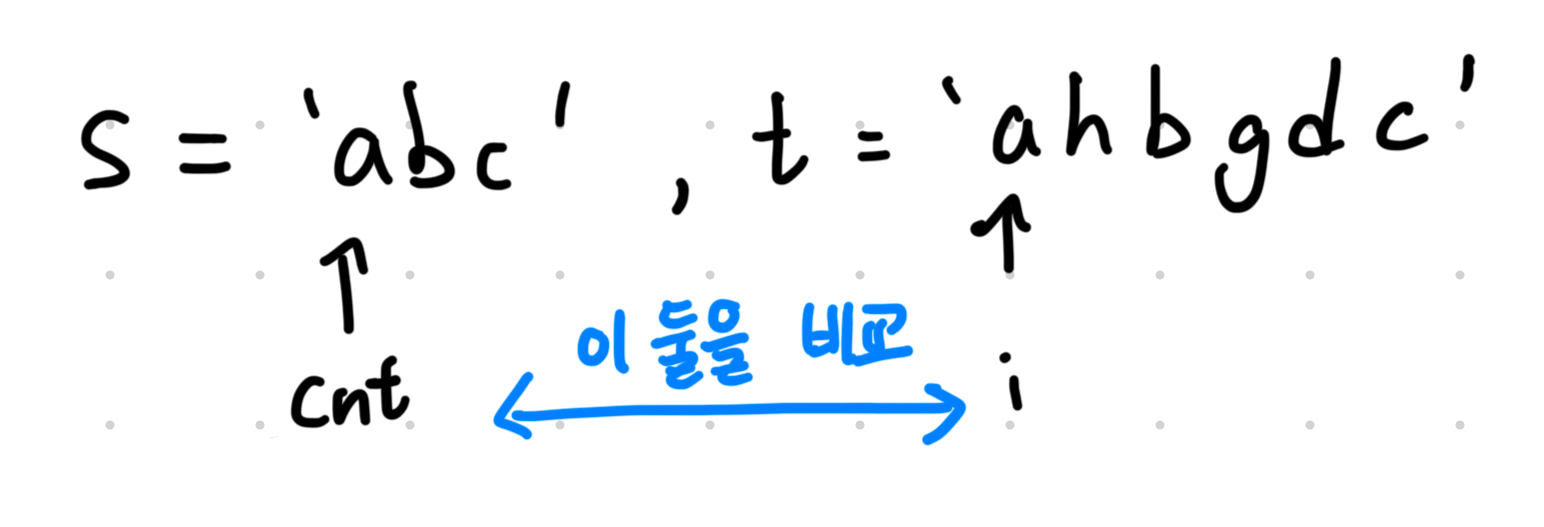
이러면 앞서 있던 인덱스에서 발생하는 문제를 없앨 수 있다.
그리고 cnt가 무사히 s의 마지막 인덱스 값이(여기서는 cnt == S-1) 된다면 True를 뱉어주면 되고, 그 이외에는 모두 False가 된다.
'리트코드 알고리즘 > 리트코드 easy' 카테고리의 다른 글
| (간단한 코드)리트코드 228. Summary Ranges (0) | 2024.12.10 |
|---|---|
| (간단한 코드)리트코드 14. Longest Common Prefix (0) | 2024.12.08 |
| (간단한 코드)리트코드 121. Best Time to Buy and Sell Stock (0) | 2024.12.08 |
| (간단한 코드)리트코드 1768. Merge Strings Alternately (0) | 2024.12.03 |
| (간단한 코드)리트코드 2239. Find Closest Number to Zero (0) | 2024.12.02 |